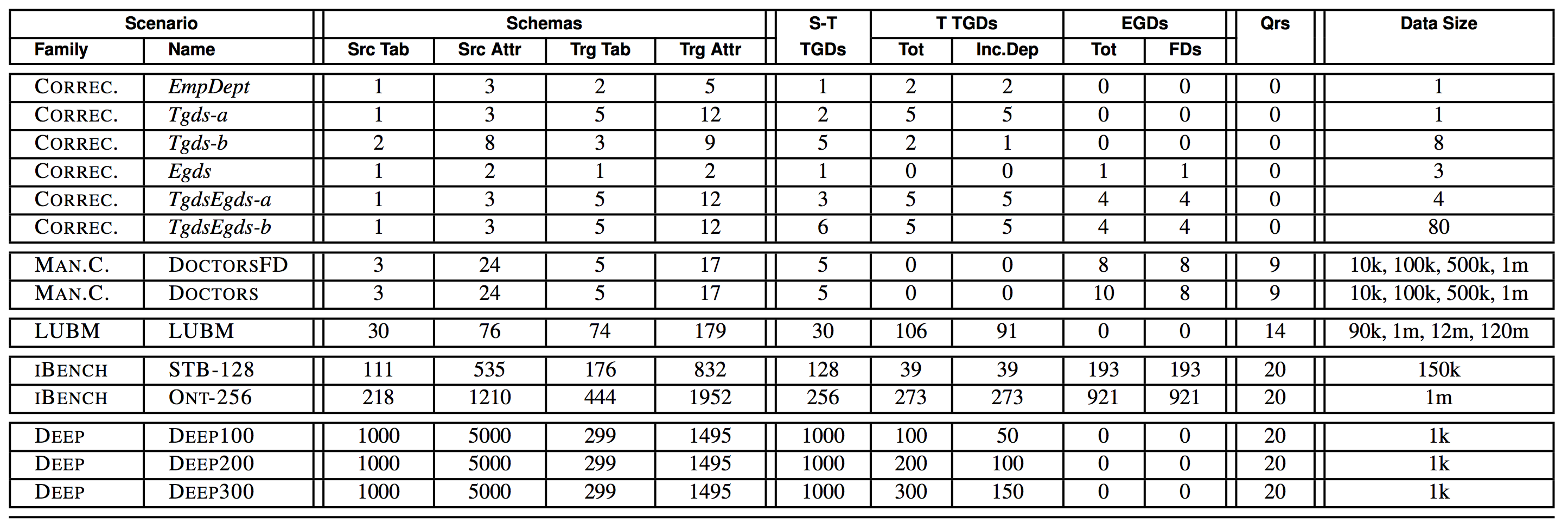
Test Scenarios
Our benchmark consists of a total of 23 scenarios, each scenario consisting of source and target schemas, constraints, queries, and source data. The scenarios belong to 5 different families, detailed in Table 2. The first one includes 6 small scenarios used as correctness tests for data exchange. The others were used for performance testing, both in data exchange and query evaluation, and for correctness tests based on query results. Two of these, IBENCH and LUBM, are based on known standards, either from the database or the Semantic Web community. The other two, MANUALLY CURATED and DEEP, we developed ourselves in order to test specific aspects of the chase.
Test Infrastructure
The Common-Format Parser
The tools under evaluation differ widely on their assumptions about input. To this end, we standardized the way in which tests were run, creating our own “common format” for constraints, queries, and also data. A standard parser for the common format was developed. Based on the parser, a converter was created for each tool.
Instance repair tool
Generating scenarios with EGDs and large source instances is a complex task since, due to the size of the source instance, it is difficult to ensure that no EGD chase step fails. For example, the data generated by ToXgene is not guaranteed to be consistent with a collection of TGDs and EGDs, and in fact the chase fails on all input instances that we initially produced using ToXgene; hence, this problem is not merely hypothetical. To deal with this problem, we developed a simple instance repair tool.
The Target TGD Generator
Our major set of experiments concern performance. In addition to being able to generate source instances of different size, one primary concern was to have data-exchange scenarios with a significant number of s-t TGDs, target TGDs, and target EGDs. To do this, we used a custom target TGD generator. The generator allowed us to generate weakly acyclic TGDs (where the chase terminates), while controlling the depth and complexity of some of the scenarios, and to complement existing scenarios with additional target TGDs to increase their level of difficulty.
The Query Generator
Query answering experiments are about finding the certain answers to a set of given queries, and thus we needed a method to generate interesting queries on the target instances. Besides leveraging known benchmarks that come for a set of queries, like LUBM, we had to develop our own query generator. The query generator was essential in order to have queries with non-empty results. In addition, on large schemas it allows us to control the number of joins – we generated queries with up to 7 joins – and therefore the complexity of query evaluation.
The Homomorphism Checker and Data Exchange Correctness Tests
It was important to test not only the performance of the tools but also their correctness. We thus developed a tool capable of testing homomorphisms, mutual homomorphisms, and isomorphisms between database instances. The tool uses essentially a brute-force approach, and therefore can be used only on relatively small instances, of a few thousands tuples at most. Thus our correctness test for data exchange consisted of a collection of test scenarios for which the chase result was small. The scenarios covered standard examples from some of the prior papers and surveys on the chase, including cases where TGDs and EGDs interact, where the chase fails, and scenarios that distinguish termination conditions based on various acyclicity conditions. We then used the homomorphism checker to check for homomorphic equivalence among the outputs of the given tools.
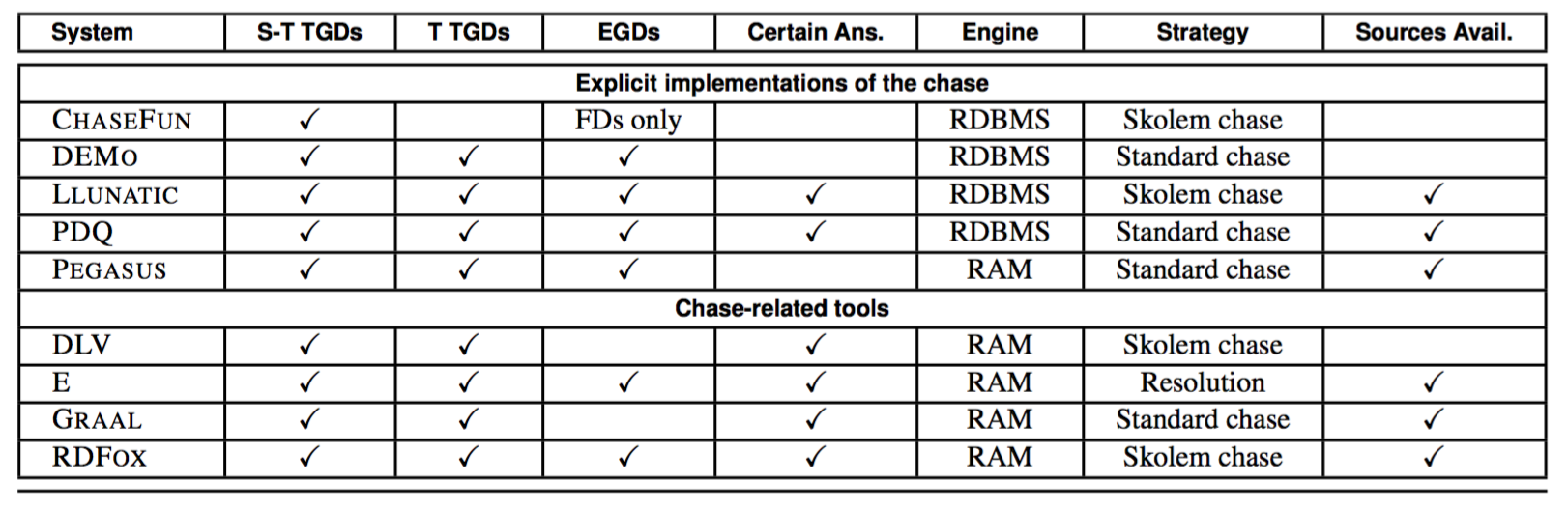
Systems Under Evaluation
Our main goals are to determine whether available chase implementations can support data exchange and query answering in absolute terms, and to investigate the implementation decisions that are most relevant to performance. To answer these questions, we identified nine publicly available chase-related systems. The table at the bottom shows the main aspects of each system. Moreover, we group all systems based on their motivation.
Chase for data exchange
- ChaseFun - A. Bonifati, I. Ileana, and M. Linardi. Functional Dependencies Unleashed for Scalable Data Exchange. In SSDBM, 2016
- DEMo (Data Exchange Modelling) R. Pichler and V. Savenkov. DEMo: Data Exchange Modeling Tool. PVLDB, 2(2):1606–1609, 2009
- Llunatic - F. Geerts, G. Mecca, P. Papotti, and D. Santoro. The LLUNATIC Data-Cleaning Framework. PVLDB, 6(9):625-636, 2013 http://db.unibas.it/projects/llunatic/
Chase for query reformulation
- PDQ - M. Benedikt, J. Leblay, and E. Tsamoura. Querying with access patterns and integrity constraints. In VLDB, 2015 http://www.cs.ox.ac.uk/projects/pdq/home.html
- Pegasus - M. Meier. The backchase revisited. VLDB J., 23(3):495–516, 2014
Chase for query answering
- Graal - J.-F. Baget, M. Leclère, M.-L. Mugnier, S. Rocher, and C. Sipieter. Graal: A toolkit for query answering with existential rules. In RuleML, 2015 https://graphik-team.github.io/graal/
Chase-related tools
- DLV - N. Leone, G. Pfeifer, W. Faber, T. Eiter, G. Gottlob, S. Perri, and F. Scarcello. The DLV system for knowledge representation and reasoning. TOCL, 7(3):499–562, 2006 http://www.dlvsystem.com/dlv/
- E - S. Schulz. System Description: E 1.8. In LPAR, 2013 http://wwwlehre.dhbw-stuttgart.de/~sschulz/E/E.html
- RDFox - B. Motik, Y. Nenov, R. Piro, I. Horrocks, and D. Olteanu. Parallel Materialisation of Datalog Programs in Centralised, Main-Memory RDF Systems. In AAAI, 2014 https://www.cs.ox.ac.uk/isg/tools/RDFox/
Experimental Results
We ran all tests on a server with 6 physical Xeon v3 cores running at 1.9GHz, 16 GB of RAM, and a 512 GB SSD, running Ubuntu v16. Our configuration is thus not very far from that of a high-end laptop. The results are shown at the follow link https://dbunibas.github.io/chasebench/times.pdf (times are in seconds).
People
- Michael Benedikt - University of Oxford
- George Konstantinidis - University of Oxford
- Giansalvatore Mecca - University of Basilicata
- Boris Motik - University of Oxford
- Paolo Papotti - Arizona State University
- Donatello Santoro - University of Basilicata
- Efthymia Tsamoura - University of Oxford